Hello,
I’ve researched this topic, and I found two types of threads: one that suggests that loops are necessary for those that need to adjust lacing and list formats, and the other that discusses either LoopWhile or List.Map. I’ve read up on both of those, but they’re not exactly sinking in, and I’m here to ask what path you suggest I investigate to accomplish the following task.
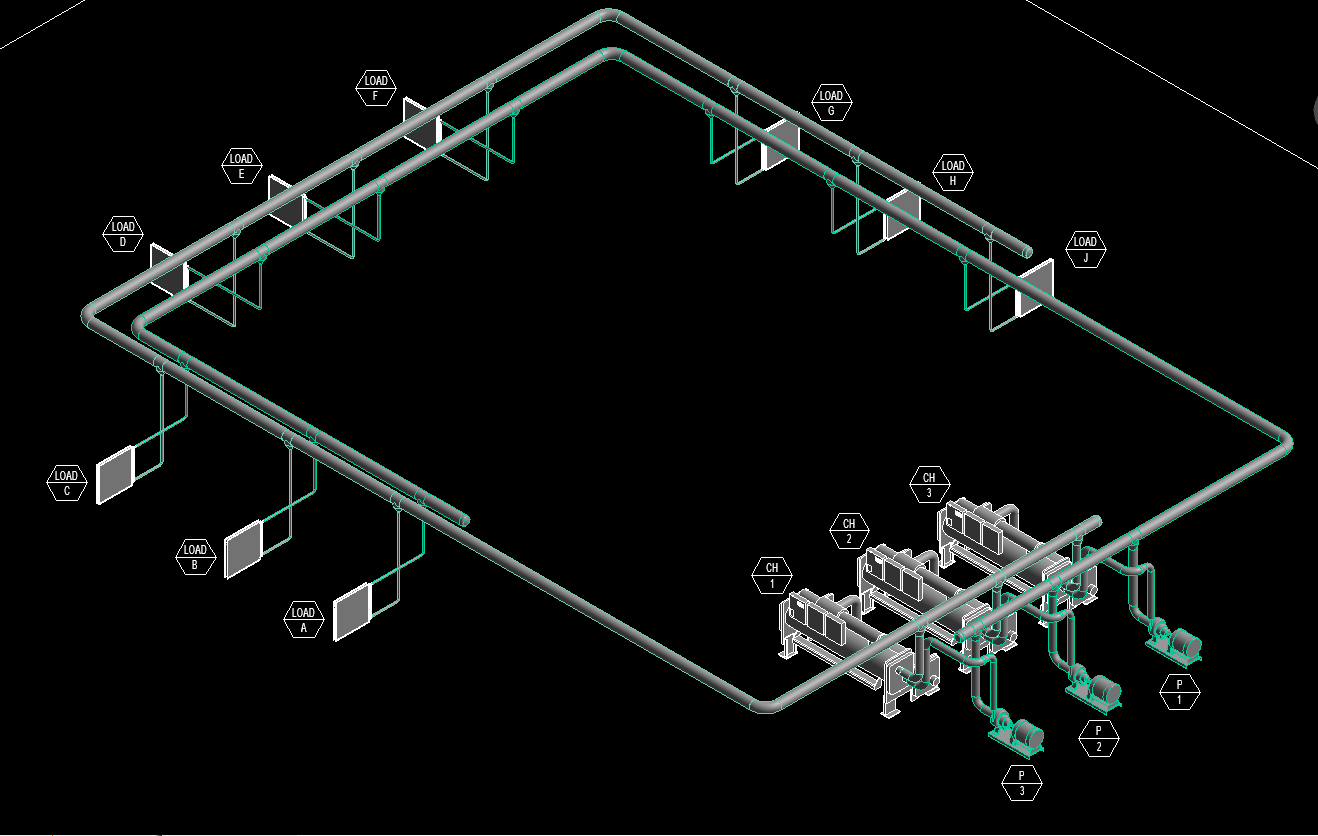
I have a sandbox Revit file with chillers, pumps, and coils. The coils are meant to represent different loads. These are identified as LOAD-A, LOAD-B, etc.
I also have a test XLS file that simulates the cooling load profile over the span of five datasets. The loads are listed in rows, and the data sets are by column.

What I’m doing is taking these loads in XLS, calculating the flow rate for each load, and writing this info to the flow parameters for the loads (the coils). The data set for flow rates to be written to Revit coils is circled in red. The transpose list is a series of sublists of datasets; flow rates for dataset 1, then dataset 2, etc. until you reach the end of the list, which is dataset 5 from the XLS file.
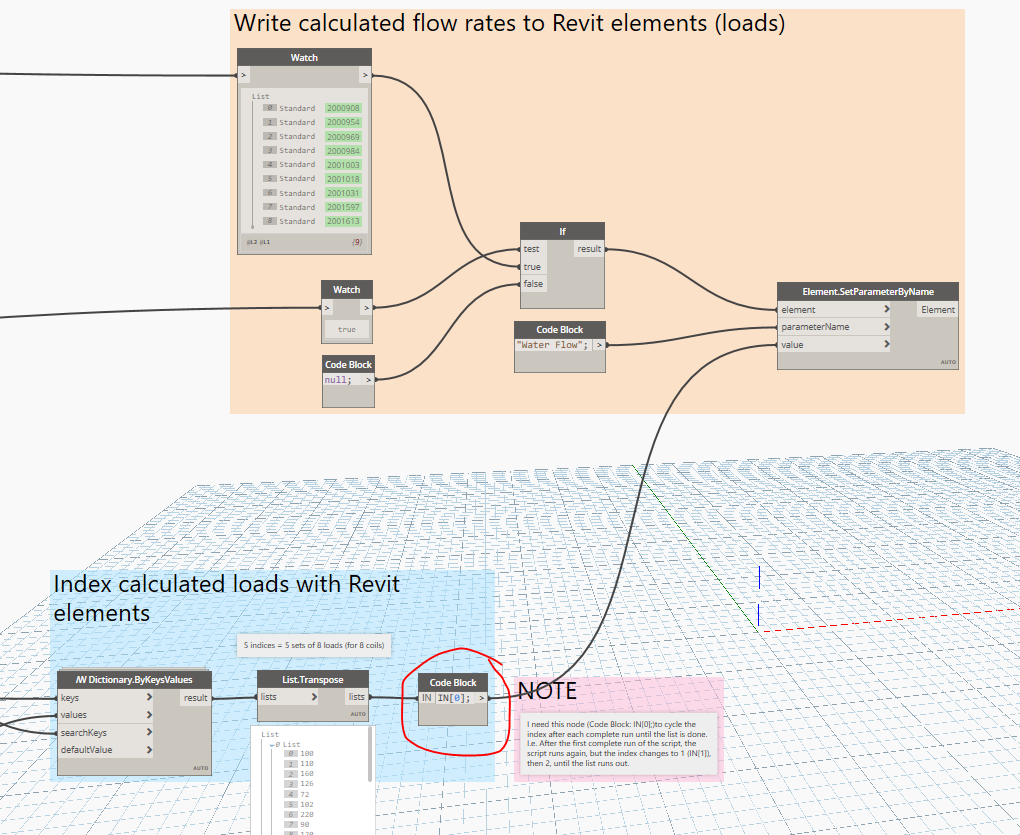
There is another string of scripting that then pulls pipe flow and velocity data from Revit as a result of the updated load flow rates. The data is collected and written to another sheet in the same XLS file.
This works perfectly fine for running one data set at a time, but what I want to do is change the index that is analyzed and write the new flow data to excel in the next set of columns over. I want to keep running this until I’ve exhausted the lists in the List.Transpose node. The end-goal is something that looks like this:
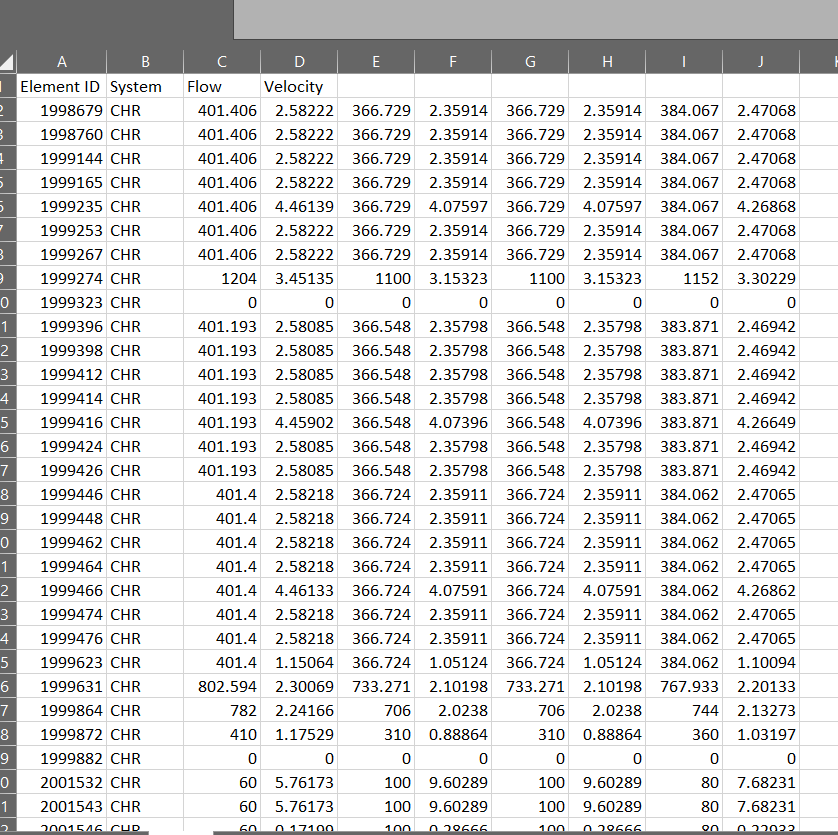
To get the sample output, I had to manually change the index (circled in red two pictures up) to the next value, and change the column start for writing to XLS by two values (two columns to the right) for each run.
From what I’ve read, I imagine this is a tad more complicated than other posts I’ve read dealing with lacing since the second string relies on the output of the first string. I’m actually hoping that my previous statement just comes from ignorance and that it’s not actually as difficult as I make it out to be.
Anyway, I hope to get some feedback from you all. I’ve attached/linked the appropriate files for your perusal. I’m using archilab and Springs nodes; apologies if I’ve missed listing any others.
Revit file: https://drive.google.com/drive/folders/1Q3mu_e1kwFD8R-dCD7chVTZ5Ar7b5vVs?usp=sharing
Hydraulic Analysis.dyn (196.7 KB)
TEST load file.xlsx (14.4 KB)