Interesting topic. Just to understand a bit more…
are the current revisions in the views or on the sheets?
depending on which, it will change the extraction logic drastically.
if it’s a view based revision, you’ll need to extract from the views and get the sheet number references
if it’s a sheet based revision, the extraction should begin from the sheets. you may not be able to extract the viewport reference easily. need to consider building a bounding box for the viewport size and target the elements within.
the logic pathway could go many ways but it’s good to understand how the revisions are being modelled first for a start I feel.
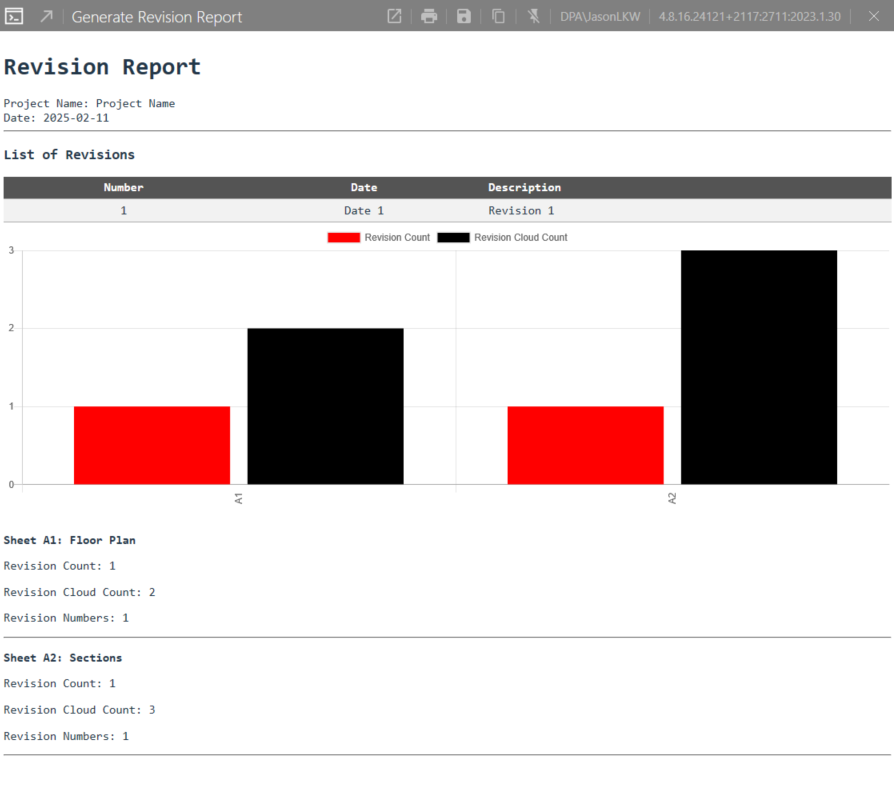
thanks for the suggestions. I do have pyRevit but I was hoping for a more detailed report like the one you generated. I see a node called “lists.clean” is that a custom node? The only one I see when I type that in is the “list.clean” command, and requires a “preserveIndices” input, the icon also looks different.
import clr
import sys
import System
#import Revit API
clr.AddReference('RevitAPI')
import Autodesk
from Autodesk.Revit.DB import *
import Autodesk.Revit.DB as DB
#import transactionManager and DocumentManager (RevitServices is specific to Dynamo)
clr.AddReference('RevitServices')
import RevitServices
from RevitServices.Persistence import DocumentManager
from RevitServices.Transactions import TransactionManager
doc = DocumentManager.Instance.CurrentDBDocument
import pandas as pd
from openpyxl.worksheet.table import Table, TableStyleInfo
from openpyxl.utils import get_column_letter
def autosize_columns(df, ws):
"""
A function that sets the width of each column in a given worksheet (ws) based on the maximum length of data in each column in the Pandas DataFrame (df).
Args:
- df: Pandas DataFrame containing the data to be written to the worksheet.
- ws: Worksheet object representing the worksheet where the data will be written.
Returns: None
"""
margin = 7
lstvalues = df.values.tolist()
lstColvalues = df.columns.values.tolist()
column_widths = []
for row in [lstColvalues] + lstvalues:
for i, cell in enumerate(row):
current_lenCell = len(cell) if cell is not None else 1
if len(column_widths) > i:
if current_lenCell > column_widths[i]:
column_widths[i] = current_lenCell
else:
column_widths += [current_lenCell]
for i, column_width in enumerate(column_widths, 1): # ,1 to start at 1
ws.column_dimensions[get_column_letter(i)].width = column_width + margin
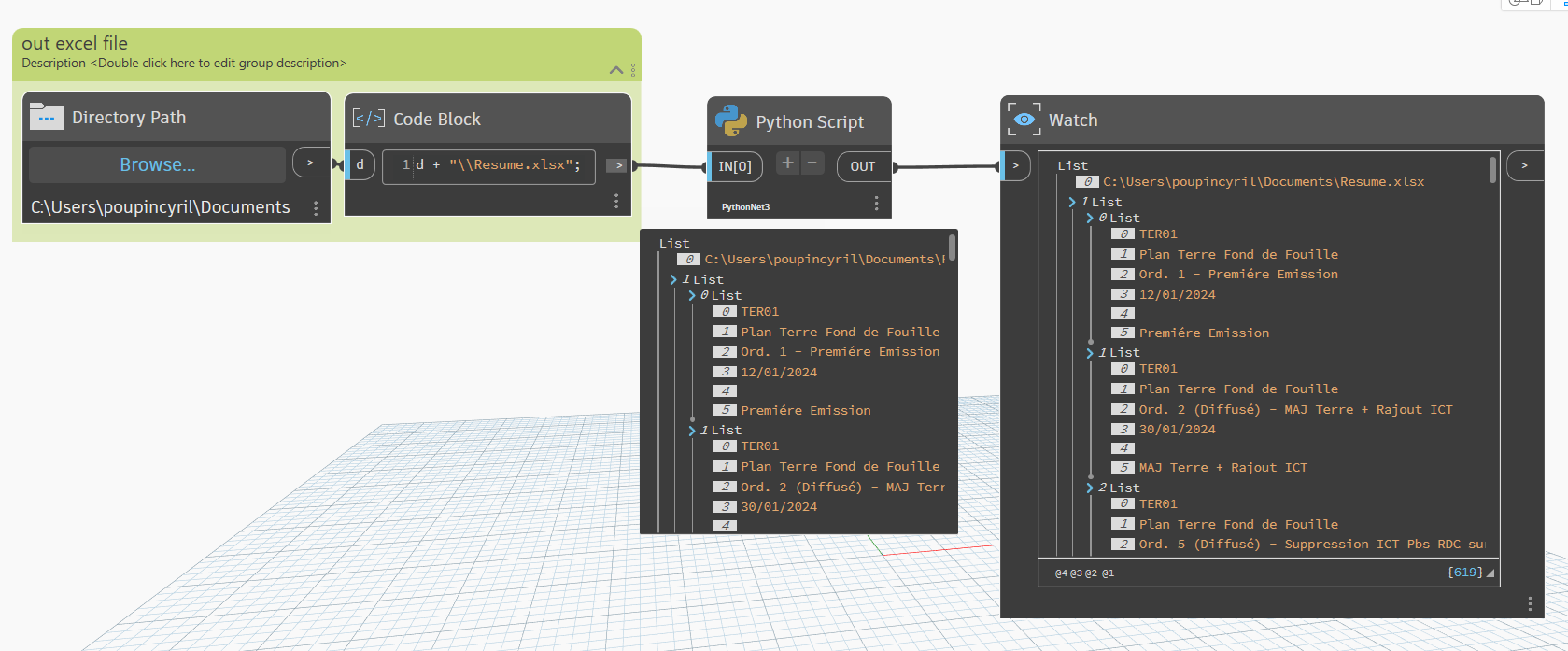
out_xls = IN[0]
lst_value = []
all_sheets = FilteredElementCollector(doc).OfClass(DB.ViewSheet).WhereElementIsNotElementType()
all_revision_clouds = FilteredElementCollector(doc).OfClass(DB.RevisionCloud).WhereElementIsNotElementType()
for sheet in all_sheets:
all_views_in_sheet = [doc.GetElement(xId) for xId in sheet.GetAllPlacedViews()]
# add primaries views
all_viewIds_in_sheet = [v.GetPrimaryViewId() for v in all_views_in_sheet] + [v.Id for v in all_views_in_sheet]
all_additional_revisionIds = sheet.GetAdditionalRevisionIds()
all_revisionIds = sheet.GetAllRevisionIds()
all_revisions = [doc.GetElement(xId) for xId in sheet.GetAllRevisionIds()]
all_revisions.sort(key = lambda x : x.SequenceNumber )
for rev in all_revisions:
onwerView = ""
rev_clouds = [cld for cld in all_revision_clouds if cld.RevisionId == rev.Id and cld.OwnerViewId in all_viewIds_in_sheet]
if rev_clouds:
onwerView = doc.GetElement(rev_clouds[0].OwnerViewId).Name
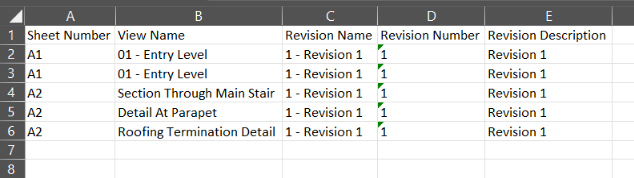
lst_value.append([sheet.SheetNumber, sheet.Name, rev.Name, rev.RevisionDate, onwerView, rev.Description ])
with pd.ExcelWriter(out_xls, mode="w", engine="openpyxl") as xlsx:
df = pd.DataFrame(lst_value, columns = ["SheetNumber", "SheetName", "RevisionName", "RevisionDate", "OwnerViewCloud", "RevisionDescription"])
#
df.to_excel(xlsx, sheet_name="Revision", index=False)
# get worksheet
ws = xlsx.sheets["Revision"]
table = Table(displayName="Table_Revision", ref="A1:" + get_column_letter(ws.max_column) + str(ws.max_row))
# add a default style with striped rows and banded columns
style = TableStyleInfo(name="TableStyleMedium9", showFirstColumn=False, showLastColumn=False, showRowStripes=True, showColumnStripes=False)
table.tableStyleInfo = style
ws.add_table(table)
autosize_columns(df, ws)
OUT = lst_value
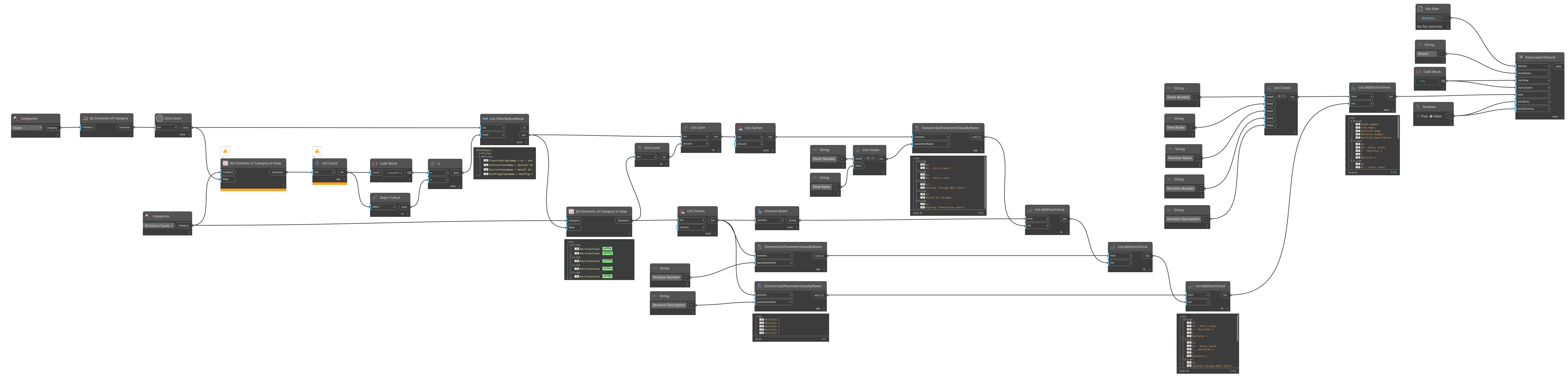
I believe there are two types of list clean. One that preserves the indices for you and the other cleans the null values disregarding the index arrangements.
For these Views, I believe the null values belongs to the view templates hence why it appears as such.
No need for concerns though. They perform the same way so you could set the boolean to false as replacement.
Secondly, my approach to dynamo has always been to utilize the Core nodes first.
We shouldn’t be too reliant on the custom nodes in the beginning of Dynamo programming.
This allows us to understand the base capabilities of Dynamo.