As the title describes, I have a list of family instances, and I’d like filter down by random. So far the best I’ve come up with is create a Math.RandomList and filter by a dimension (since it’s 0…1 then something like x > 0.5).

Hi mate,
Not sure if this will help but… You can try a different method of “filtering”.
See below. As for the max value, you could link to the list count as what you’ve done.

Cheers.
Where do you get that new node from? Also, how would you go about increasing the count of selected items? Is it the remap range or would you add a multiplier? Thanks!
That is one method. Another method would be a List.Shuffle followed by a List.TakeItems.
The advantage rof the Math.Random method is that you get a more random feel as List.TakeItems is difficult to add additional entropy to without adding another node for randomization.
The big advantage to using the Math.Random is that you can filter the list in one go (List.FilterByBoolMask) rather than having to sequentially take and drop items.
Thanks @jacob.small I saw you mention ListShuffle in another post (I always google before asking a question here) but for the life of me I cannot see where it would fit. Are you shuffling the original list? What are you doing after you shuffle it? Aren’t you left with the entire original list after that, just one that has been reordered? Actually as I’m typing this perhaps it’s starting to make sense… Are you shuffling then grabbing every nth item? A simple example would be very useful.
For the FIlterByBoolMask method what would your filter rule consist of? I’m currently grabbing everything that’s < 0.5 from the random and hoping to get a 50/50 true false output but it doesn’t seem very elegant. Thanks!
Here are some examples of sampling data randomly. Each languarge has its benefits but you can see that the use of Bool Filters does have the possibilty to add to the runtime. I know we are talking milliseconds here, but it all adds up when you are coding…

3 Likes
@Ewan_Opie That is extremely helpful as I’m actually working on a rather large data set. Out of curiosity, why is the DesignS faster than the node even though it’s the exact same function? Thought that was odd. Thanks!
Try building a simple ‘toy’ problem.
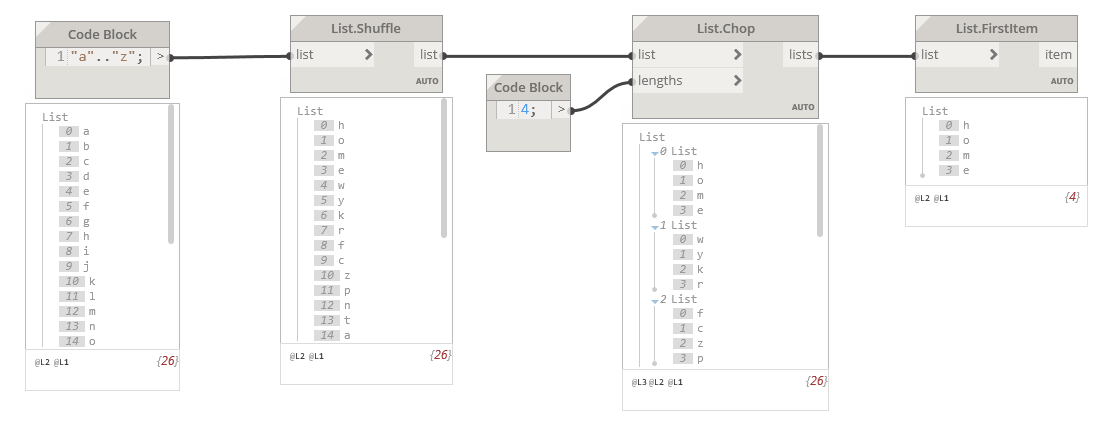
In a code block type “A”..”I” - this will create a list of letters from A to I.
Wire the list of letters into a List.Shuffle node. The result will be a miss-ordered list of letters.
Next wire the original list of ordered letters into a List.Chop node, with the count value set to 3. The result should be something like [ [“A”, “B”, “C” ], [“D”, “E”, “F”], [“G”, “H”, “I”] ].
Now try feeding this list into a List.Shuffle node. The result should be a misordered set of 3 letters (so it’s unlikely that ABC will be first, though possible).
Now lastly, try changing the list level on the List.Shuffle to @L2, so that the function is run on the lists of letters instead of the outermost list of lists of letters.
The same concept can be applied to your panels, but the panels will be harder to visualize than the alphabet.
I did wind up demoing this concept (using the Math.RandomList method) in the community conversation last week. I hope to see that posted next week (along with the graph - I finished annotating it but failed to post it before I had to head off for a long weekend with my family).
1 Like
No worries. I look forward to seeing it. Thanks @jacob.small!
1 Like
@jasonlkw question. Sometimes the Math.Random + Math.Round creates duplicates. What would be a good strategy to cut down on duplicates? Thanks!
Actually, @jacob.small solution is much cleaner. I used List.UniqueItems to combine the duplicates. This may still give you the random numbers but it might not have a controllable list amount.
Yea, I ended up using your method because it gave me a little more control. I was able to improve the duplicate by increasing the range in the first remap and moving the rounding function one step ahead. I hope this doesn’t add too much computing on top of what it’s already doing.

The @jacob.small method might be better. See below.
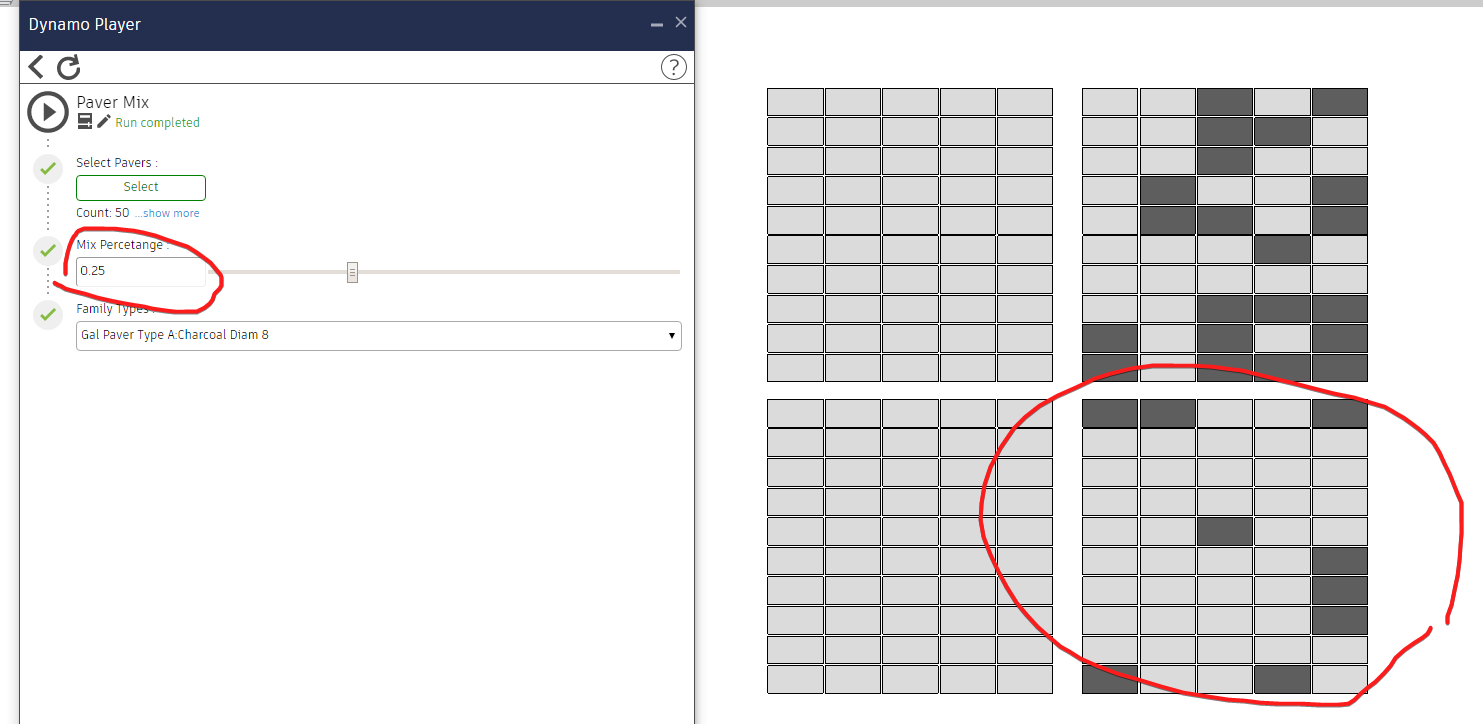
Oh interesting. I was able to adapt your node to specify a certain percentage of random items to be grabbed. For instance, I can grab 25% of random items from total list:
I guess I could apply the percentage to the List.Chop by multiplying 0.x by list length. Hmm. Yea, I guess either works. Which do you think is faster?
Haha! That’s an interesting graph on the tiles.
Either would work actually but I believe the shuffle + chop does make it faster because it’s more direct.
You could combine the whole lot into a designscript to “make it sing”
inp1 = list;
inp2 = ratio;
shf1 = DSCore.List.Shuffle(inp1);
chp1 = DSCore.List.Chop(shf1,inp2);
fst1 = DSCore.List.FirstItem(chp1);
Somewhere along those lines.
I just rebuilt it with the List.Shuffle and it does feel faster. Probably because the MathRandom and MathRound might add extra computing. I like it! I really do need to learn DesignScript tho…
1 Like
DesignScript is quite rewarding. Vikram Subbaiah does an amazing job at it. You should check him out.
1 Like