Hi All,
Very new to Dynamo, and hope my question is simple!! I have just run a Sentence Case script which worked perfectly… however in some cases where strings for example “1.8mm” were present within the file, the script has now updated this to “1. 8mm”.
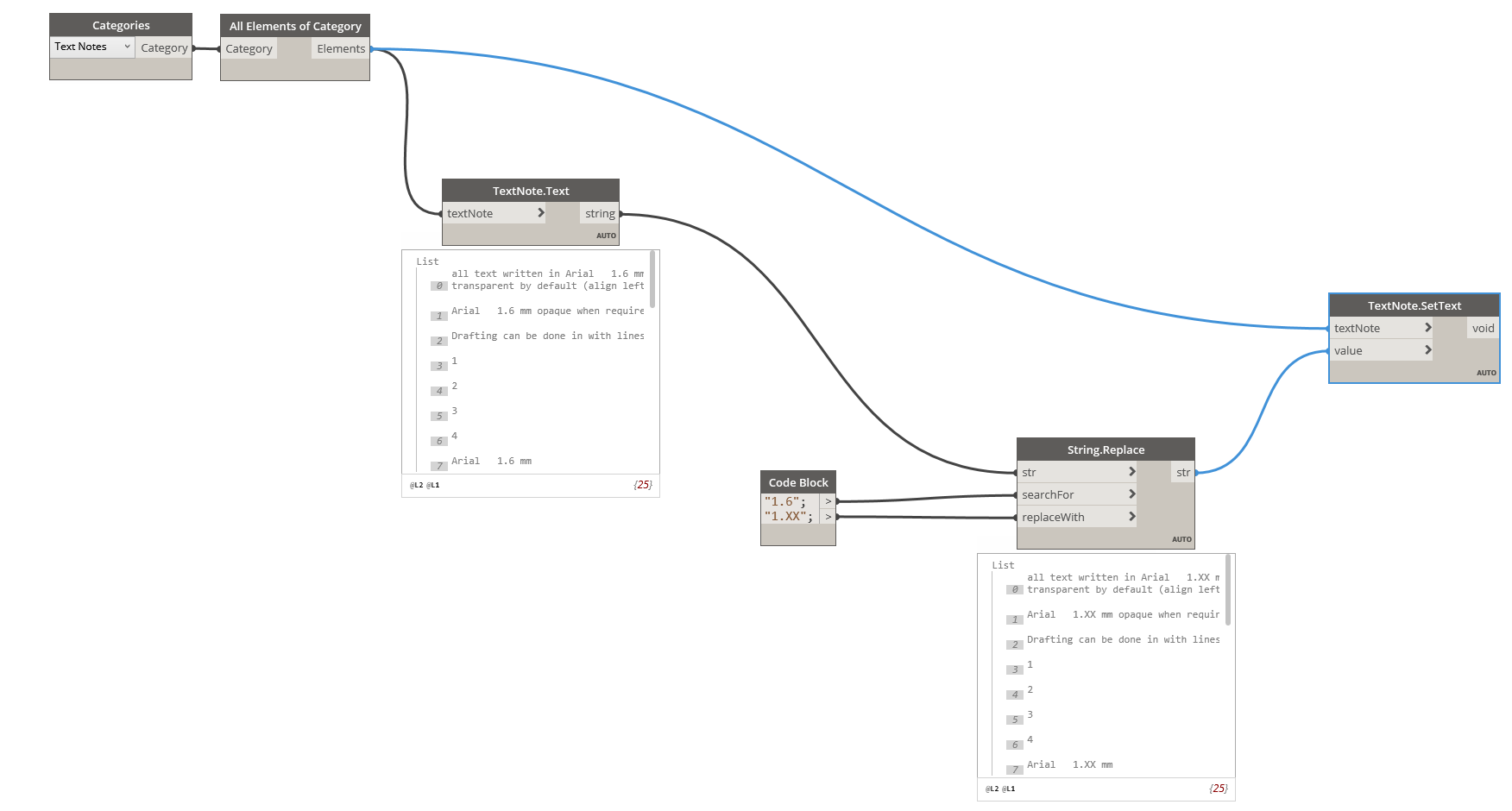
I understand this to be relating to the python script and it makes sense that a space is included after the decimal point, however I would now like to create a list and use “String.Replace” to find all 1 decimal point numbers and remove the unwanted space.
My test sample is below… two problems, the list doesn’t seem to work? And I can’t see any text updating in Revit?
Any help would be ideal!
@salvatoredragotta this is a great solution and a perfect example of ‘not overcomplicating things.’
Great job.
@salvatoredragotta thanks for your assistance! that’s got the text swapping out nicely!!!
One further query… is there a way to make the code block apply the same logic, but for a sequence of “strings” and replacing them with a similar sequence? I’m trying to remove spaces after a number with a decimal point (project wide)
For instance: I current have “1. 8mm” and would like to change to “1.8mm”
Search for “. 1” replace with “.1”
Search for". 2" replace with “.2”
Search for". 3" replace with “.3”
Search for". 4" replace with “.4”
Search for". 5" replace with “.5”
Search for". 6" replace with “.6”
Search for". 7" replace with “.7”
Search for". 8" replace with “.8”
Search for". 9" replace with “.9”
I figure this would search through all decimals instances and be able to remove the unwanted space?
Thanks in advance Dynamo guru’s!
Just replace the code block values with the image below.

Thanks Scott… but won’t that update all Sentence Case strings as well? I’m hoping to just isolate number sequencing as outlined above… It that makes sense?
For examples where a text note states “1.8mm thick” for instance… I ran a Sentence case script which worked great but didn’t recognize numbers, instead inserted a space after every bullet point.
Thanks heaps!
Could you just filter to find only text notes that contain “mm” first? Then move into the string replace routine. That way it will isolate just text containing the dimensions?
Unless there is text that contains a dimension and then additional sentences?
Would probably need to see a bigger list of the text in the file to see how to filter out just the dimensions.
Thanks
@Scott_Crichton, thanks for your reply… not quite sure I follow your filter then replace logic, hoping to run replace through the entire project, but if filter makes it easier then I’ll look into that.
With that said, here’s a template file which I have tried the script on, it show’s a few examples, but in reality I would like the script to cover all texts notes with numbers that include 1 decimal point if that makes sense?
The problem was created from my sentence case script… perhaps there’s something in the pyhton script, but I’m not sure how to edit it unfortunately, that’s why I’m looking to create a “remove space” script.
SENTENCE CASE SCRIPT - some nodes from rhythm
REPLACE SCRIPT
@Ashton_at_Hierarchy Please start a new topic for the next query.