Hello Everybody!
I have a basic level of dynamo,
today I need your help to solve a tip.
I want to give a new name to wall types with its layers.
So for example, a wall composed of: panel, isolation, panel will be called “pan-isol-pan”
or a wall composed of brick, isolation, brick, peinture, will be called “bric-isol-bric-pein”.
I have tried to do something, but I know I’m far to reach my point.
Can you please help me?
Hi,
it seems that the problem it’s concerning just the joining of the strings representing your materials.
If so, here a possible solution to achieve the composition you are looking for:
Hello @Giuseppe_Dotto!!! I’m one of your biggest fan!!
Thank you , I tried to use your method.
The problem is that it works just for some values and not for them all.
I don’t understand why…
Can you give a look?
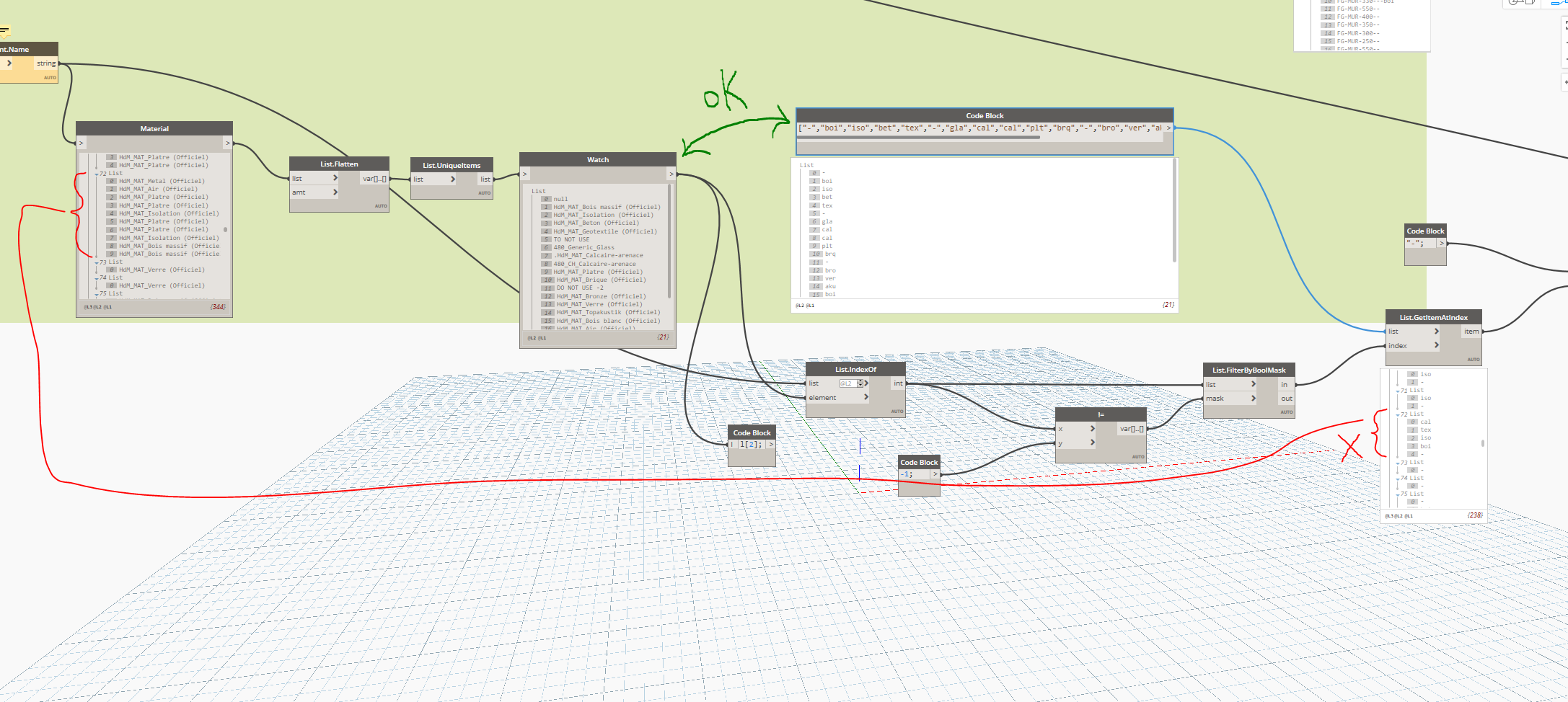
For this solution, because of the need of flatten the list, I would suggest adding one else at the end in order to let her possible to chop the flattened list with the same lengths of the previous one.
liste, liste_search, liste_ab=IN
z=[]
for i in liste:
if i in liste_search:
b=liste_search.index(i)
z.append(liste_ab[b])
else:
z.append("-")
OUT=z
Hello everybody!
Sorry to disturb you again, I’m having some issues using the script…
When I insert it in a project with many wall types, the “translation” with materials and codes doesn’t really work properly.
Also, it gives an error at the beginning of the script, that says some types are not convertible. And Revit doesn’t apply the new names in the project browser family. (It seems like Dynamo cannot push the new information in Revit).
First issue: Can you check if the list exiting from the node “Element.Name” has the same size as the list exiting from the “in” key of the node “List.FilterByBoolMask”?
Second: Are you able, by looking inside the list, which kind of element material are not convertible? Can be that the “element” that causes the problem is a null or an empty list, in any case, since you are working just with strings, I’ll suggest you convert all the output of the element.Name into a string by using the “String from Object” node
Hi @Giuseppe_Dotto, thank you for the answer…
The list existing from node “Element.Name” has not the same size as the list exiting from the “in” key of the node “List.FilterByBoolMask”, which is a problem , but I don’t know how to solve it…
I tried to use string from object but I think dynamo is still annoyed by the null values,
I charge here the dynamo file, which maybe can help the exchange20200120.test_Wall names.dyn (59.4 KB) .
Hi Fede,
Thanks for sharing the .dyn file. I tested it and by my side, it is working well. What you should do now is to understand where happens this loss of data that make the 2 lists different in size.
Since we already solved the list managing useful to create the composition of strings you were looking for, the post is becoming a bit of an off-topic.
Anyway I will suggest you another way to extract the material name and replace the node that gives you the error:
import clr
clr.AddReference('ProtoGeometry')
from Autodesk.DesignScript.Geometry import *
# Import DocumentManager
clr.AddReference("RevitServices")
import RevitServices
from RevitServices.Persistence import DocumentManager
# Import RevitAPI
clr.AddReference("RevitAPI")
import Autodesk
from Autodesk.Revit.DB import *
doc = DocumentManager.Instance.CurrentDBDocument
# INPUT
collect = FilteredElementCollector(doc).OfCategory(BuiltInCategory.OST_Walls).WhereElementIsElementType()
# Title:
# Extract walls' layer material
out = []
errors = []
for w in collect:
try:
CompNr = w.GetCompoundStructure().LayerCount
out.append( [doc.GetElement( w.GetCompoundStructure().GetMaterialId(i) ).Name for i in range(CompNr)] )
except Exception as e:
errors.append([w, str(e)])
# OUTPUT
OUT = list(collect), out, errors
As you can see, there are 3 lists coming out from the python: The first is the collection of all the wall type in the project, second is the name of the layers’ material (per each wall type) and the fourth is a special list I created for you that will collect all the wall type which materials have not been exported.
Clockwork nodes are really amazing but this is a code more customized for that situation that helps you to understand the errors and work with cleaner lists.
This last list is a composition of lists of 2 elements, the first representing the wall type that produces the error, the second describing the error itself.
p.s. note that errors can be related to the attempt of extracting material from a Curtain Wall or extracting the name of a wall’s layer material not defined (the ones)
That’s why the lists have different numbers!
How can I tell it to not list any material as unique for each wall, but repeat it all the time that is contained in the wall?
I know, this topic is a bit long now, but if you can help me solving it, I will be very happy!