Can anyone help with some python script to look at a directory and wait until a particular file is generated before continuing?
You can use the passthrough node (from the Clockwork package), but I’m not sure if you find that enough.
I’m trying to wait until a PDF is generated so I can then move its location.
Once the info is passed to the printer dynamo sees the task as done, so need a wait function to keep checking until the file actually exists
I want to essentially keep looping the node ‘File.Exists’ until the result is true
Couldn’t that be accomplished using a while loop in a python script? Once the “dummy” output is passed out of the Python node you can let your Dynamo script continue (This could be done by using codeblock with the following: {waitfor,pass}[1]
This will waitfor=Dynamooutput before it passes the information in “pass” to the next cluster of nodes in your graph.
Problem is once dynamo sends the information to the PDF driver it sees its job as done. I need to confirm that the last file being generated exists before moving on.
The loopWhile node will work fine for this:
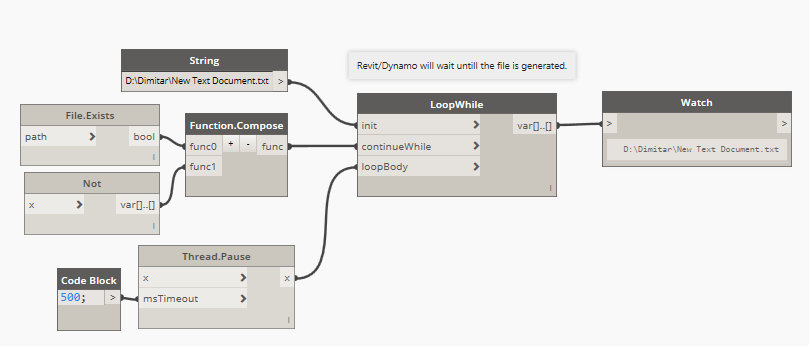
basically checking every N milliseconds if the file exists and continuing once it’s there. However you might want to do this inside of a script or have a custom node as the loop body, so that you can keep track of how many times you’ve checked so far and have a cut-off number. That way, if after 1000 checks the file is still missing and you know that the task should take no more than 5 minutes, you can forcefully break the loop.
4 Likes
Thanks very much. The loop while node makes a lot more sense now you’ve laid it out for me
Sorry stuck again, I cant figure out how to count how many times it has looped to kill the node
It’s a lot simpler to do this in python, but doing it with nodes is more fun. You’ll need two relatively simple custom nodes - one for the loop body and one for the continuation test. We’ll also have an extra input that’s going to store our check count:

Our continuation test would then verify both the count and the path and continue only when both conditions are true:

And our body would just increment the count and pause Dynamo’s thread:

You’ll know the file was found if the end count is less than the max count:

5 Likes
while I like any topic where we talk about functional programming, loop while, or imperative code in codeblocks (so they improve) - you could also try using thread.pause for a reasonable amount of time if you know the file is generated in some other part of your graph.
I did start with a general thread pause, however most of the time PDF’s are generated very quickly so didn’t want the user to have to wait for a generic pause.
But if the last PDF being created happens to be a complex sheet full of 3D views, this could take a few minutes
Thanks heaps @Dimitar_Venkov, I see where I was going wrong now. I wasn’t defining the extra input for the count
This is how I’ve accomplished what @JB86 has asked about using python. I’m new at this so sorry for the bad formatting and the unnecessary lines. I used a passthrough node to make sure the print node ran before this python node, without it the python node ran first.
import clr
clr.AddReference('RevitAPI')
from Autodesk.Revit.DB import *
from Autodesk.Revit.DB.Structure import *
clr.AddReference('RevitAPIUI')
from Autodesk.Revit.UI import *
clr.AddReference('System')
from System.Collections.Generic import List
clr.AddReference('RevitNodes')
import Revit
clr.ImportExtensions(Revit.GeometryConversion)
clr.ImportExtensions(Revit.Elements)
clr.AddReference('RevitServices')
import RevitServices
from RevitServices.Persistence import DocumentManager
from RevitServices.Transactions import TransactionManager
import os.path
from os import path
import shutil
import time
doc = DocumentManager.Instance.CurrentDBDocument
uidoc=DocumentManager.Instance.CurrentUIApplication.ActiveUIDocument
#Preparing input from dynamo to revit
filepath = IN[0]
destination = IN[1]
result = []
x = False
j = 0
while x == False:
j += 1
for i in filepath:
result.append(path.exists(i))
if all(result) == False:
result = []
time.sleep(1)
else:
x = True
if j == 30:
break
if x == True:
y = 0
for j in filepath:
shutil.move(filepath[y], destination[y])
y += 1
#Do some action in a Transaction
#TransactionManager.Instance.EnsureInTransaction(doc)
#TransactionManager.Instance.TransactionTaskDone()
OUT = x
2 Likes