I’ve got a DesignScript using an Imperative (a modified version of the Fraction.toFeet node) that works with a smaller set of data but when I throw a larget set at it Dynamo blows up. I assume there’s a limit or somethign on its usage? Relative to RAM, perhaps?
Perhaps an issue with resources or ram, or a data issue or a code issue or… really there are a lot more reasons why it wouldn’t work than I can list.
Can you share the code and a data set to test with?
The code is easy enough but I’ll need to pull a data set later tonight/tomorrow.
sTrimWhitespace = DSCore.String.TrimWhitespace;
sStartsWith = DSCore.String.StartsWith;
sSubstring = DSCore.String.Substring;
sLength = DSCore.String.Length;
sContains = DSCore.String.Contains;
sSplit = DSCore.String.Split;
sToNumber = DSCore.String.ToNumber;
sRemove = DSCore.String.Remove;
sReplace = DSCore.String.Replace;
num = [Imperative]{
s0 = "";
sA = sTrimWhitespace(s1);
sB = sReplace(sA, "-", " - ");
s1 = sRemove(sB,sLength(sB)-1,1);
n1 = 0;
n2 = 0;
n3 = 0;
n4 = 0;
n5 = 0;
q1 = 0;
sign = 1;
if(sStartsWith(s1,"-",true))
{
s1 = sSubstring(s1, 1,
sLength(s1) - 1);
sign = -1;
}
if(sContains(s1,"'",true))
{
s0 = sSplit(s1,["'"]);
n1 = sToNumber(s0[0]);
s1 = sTrimWhitespace(s0[1]);
}
if(sContains(s1," ",true))
{
s0 = sSplit(s1,[" "]);
if(sContains(s1,"- ",true))
{
q1 = 1;
}
else
{
q1 = 0;
};
n2 = sToNumber(s0[q1])/12;
s1 = sTrimWhitespace(s0[q1+1]);
}
if(sContains(s1,"/",true))
{
s0 = sSplit(s1,["/"]);
n3 = sToNumber(s0[0]);
n4 = sToNumber(sSplit(s0[1],["\""])[0]);
}
elseif(!sContains(s1,"/",true))
{
n2 = sToNumber(sSplit(s1,["\""])[0])/12;
}
if (n3 != 0 && n4 != 0)
{
n5 = (n3/n4)/12;
}
return = sign * (n1 + n2 + n5);
};Data set as XLSX
Imperative Crash.xlsx (100.3 KB)
I’m sure this ain’t as pretty as someone else would do but don’t judge me too harshly… it’s my first Python Script that didn’t involve bastardizing someone else’s!
Thanks to @Dimitar_Venkov for the start in his Feet.ToFraction node in SpringNodes
# Enable Python support and load DesignScript library
import clr
clr.AddReference('ProtoGeometry')
from Autodesk.DesignScript.Geometry import *
# The inputs to this node will be stored as a list in the IN variables.
dataEnteringNode = IN
# Place your code below this line
n1 = 0
n2 = 0
n3 = 0
n4 = 0
n5 = 0
s0 = ""
s1 = IN[0].lstrip().rstrip("\"")
sign = 1
if (s1.find("-") == 0):
sign = -1
s1 = s1[1:len(s1)]
#s1 = s1.replace("-"," - ")
if ("'" in s1):
s0 = s1.split("'")
n1 = float(s0[0])
s1 = s0[1].lstrip()
if ("-" in s1):
s0 = s1.split("-")
s0 = s0[1].lstrip()
s1 = s0
if (" " in s1):
s0 = s1.split(" ")
n2 = float(s0[0])/12
s1 = s0[1]
else:
if (not("/" in s1)):
n2 = float(s1)/12
if ("/" in s1):
s0 = s1.split("/")
n3 = float(s0[0])
n4 = float(s0[1])
if ((n3 != 0 and n4 != 0)):
n5 = (n3/n4)/12
# Assign your output to the OUT variable.
OUT = sign * (n1+n2+n5)
1 Like
I’m guessing you’re hitting some kind of a limit inside the designscript VM with your large dataset. Maybe during function lookups or storing the processed data.
@Michael_Kirschner2 this might be a good dataset for the ongoing optimisation efforts.
3 Likes
Currently testing in a Dynamo 2.5 daily build to check if any of the recent changes we have made make a difference… #playingTheWaitingGame

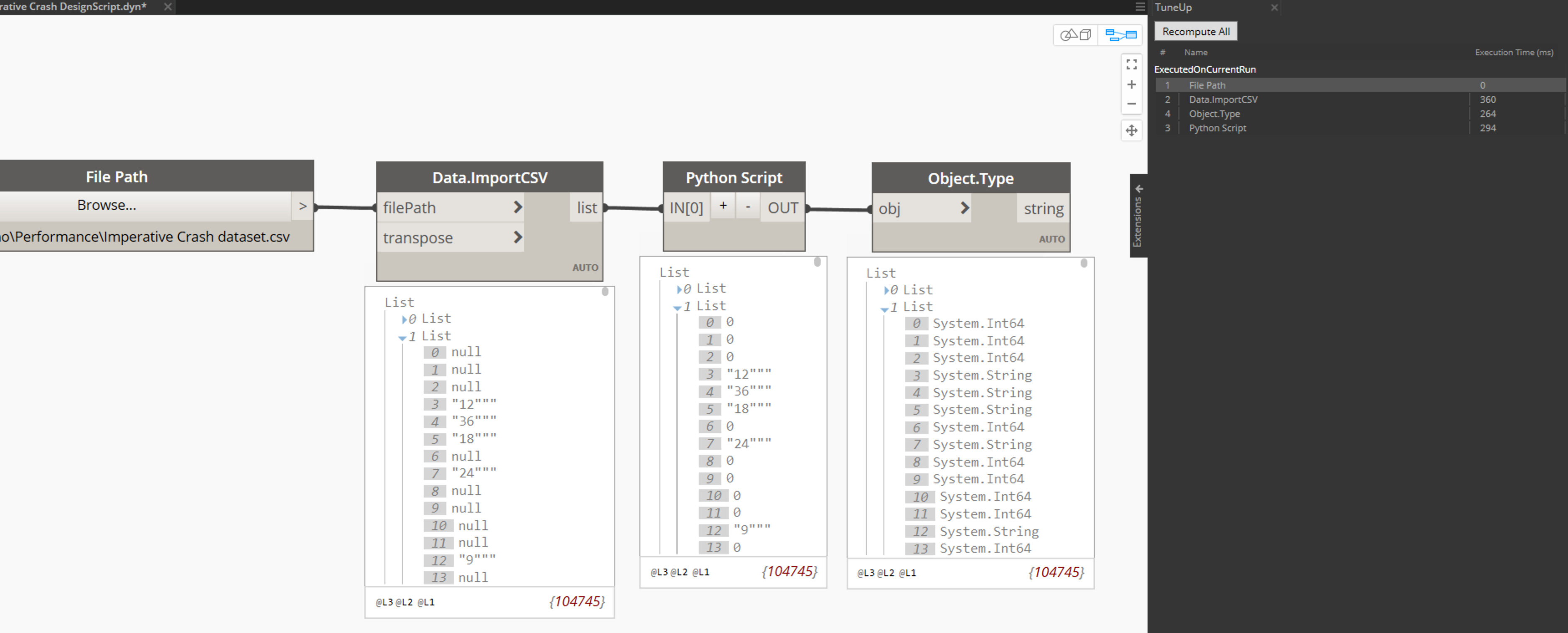
I don’t have Excel on my Parallels, so can’t test that import - hence the switch to CSV. I’ve noticed a lot of Null values coming through - are you pre-filtering these in your test? I have 104,745 Elements.
Just curious because if you don’t care about index values (Or save and repatch later) it cuts it down to 11,851 Elements 
This does execute in ~67 seconds but is throwing me a null return for the Imperative Code.
I need the nulls to become zeros which they do in the next node in the graph. The represent dimensional overrides like EQ, etc.
1 Like
one thing to keep in mind is that if you catching an exception and showing a warning and returning null from a method is really really really slow in Dynamo (and in .net) - so if you can prefill those entries with 0 or convert them to some valid data that won’t throw and return a null - that will save lots of time.
1 Like
Great to know! Might be a challenge here as they’re all strings and could be anything… can’t tell until I covert them to numbers… unless I’m missing something.
Not sure if the Excel format is doing such for you, but converting to CSV will keep nulls as null

If so, you can pre-pass the Nulls swiftly! Full execution of this step is under a second total.
data = IN[0]
results = []
for container in data:
subList = []
for item in container:
if item is None:
subList.append(0)
else:
subList.append(item)
results.append(subList)
OUT = resultsAs a starter… try embellishing this with the rest of your logic @Greg_McDowell Fully aware this is in Python, not DS but alas I’m a little rusty on that right now.
It’s currently doing the following:
- Check for Nulls -> Convert to 0
- Check for EQ -> Retain (Weirdly, not putting this here meant EQ turned into numbers)
- Checking if the item is a string -> If so, removing the single and double quotations
- Any other fallout - simply append

data = IN[0]
results = []
for container in data:
subList = []
for item in container:
if item is None:
subList.append(0)
elif item == "EQ":
subList.append(item)
elif isinstance(item, str):
if "\"" in item:
removeDoubleQuotes = item.replace("\"", "")
removeSingleQuotes = removeDoubleQuotes.replace("\'", "")
subList.append(removeSingleQuotes)
else:
subList.append(item)
results.append(subList)
OUT = resultsWhen you’re done with the if / elseif’s - you can simply convert to a number using:
strToDouble = float(string)
strToInt = int(string)Execution time here is ~1.3 seconds
Realized this morning how I could remove the nulls… check if the dimension has an override. Wouldn’t matter what the override was as I want to check them all.
The Python is working now on that dataset and I wrote another (my second!) to convert numbers into a feet/fractional inch string (I’m placing red text below dimensions where the displayed value doesn’t match the actual value).
Thanks to @john_pierson and @Dimitar_Venkov for the nodes and work that made it possible!
3 Likes
You know, looking at your code I realize that you’re saying I have both NULLs and EQs in the data! Yeah, I can pull the NULLs out first. LOL
3 Likes