Hi,
I’m wondering if i can simplify a script i built with a single node or a group that will be improve efficiency.
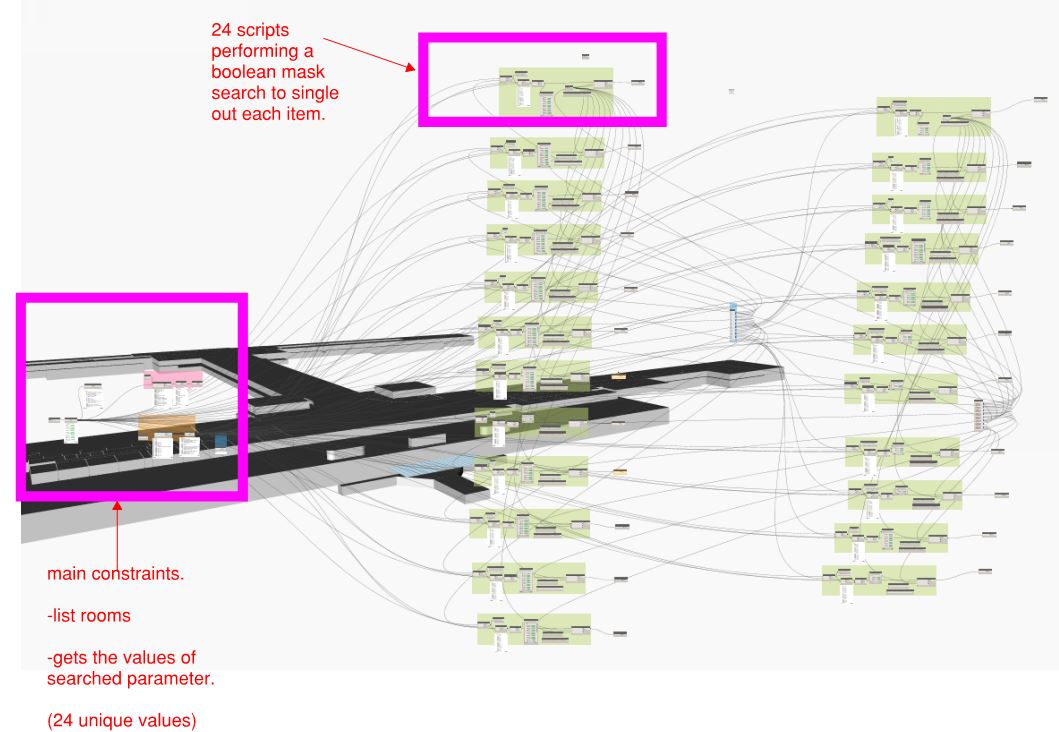
I have two lists. One is a master list of 300+ items that lists all elements of a certain category The second list is smaller with 24 items. I would like each item of the smaller list (24 items) to search the master list and output the occurrences of the 24 items separately. (Item 1 occurs 24 times in the master list - here are the list of rooms xxx)
My first run through performs the following,
- lists the room elements
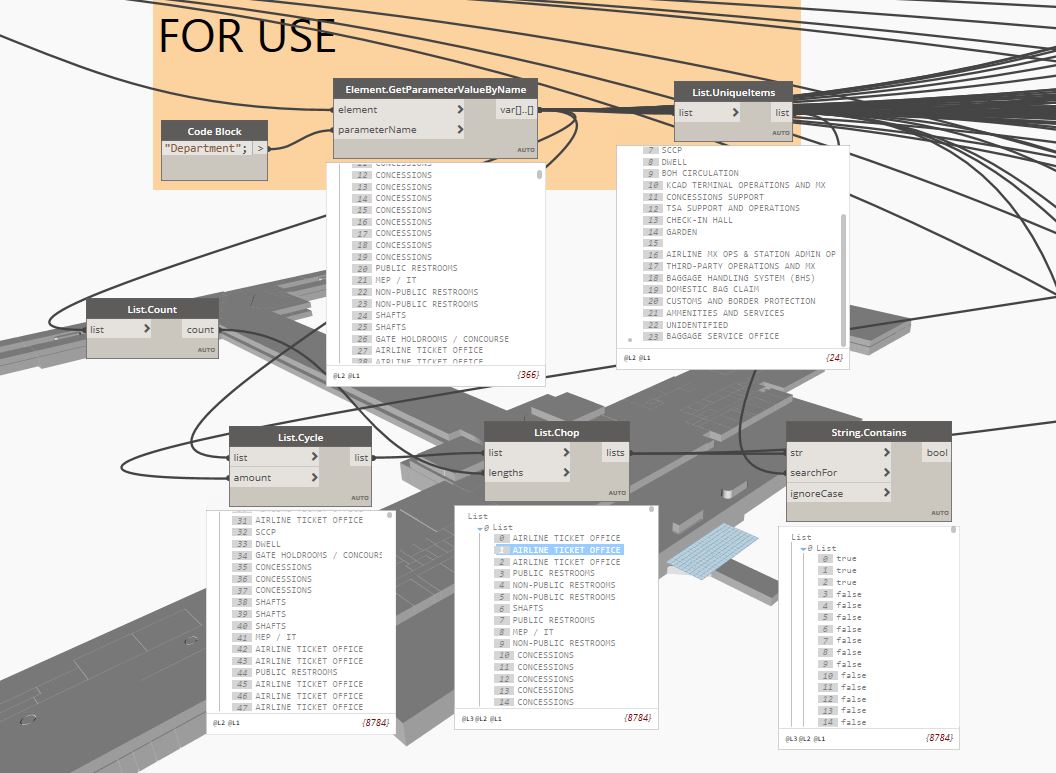
- gets the items of a certain parameter. Let’s call the parameter “department” and lists the values (We have 24 unique values.
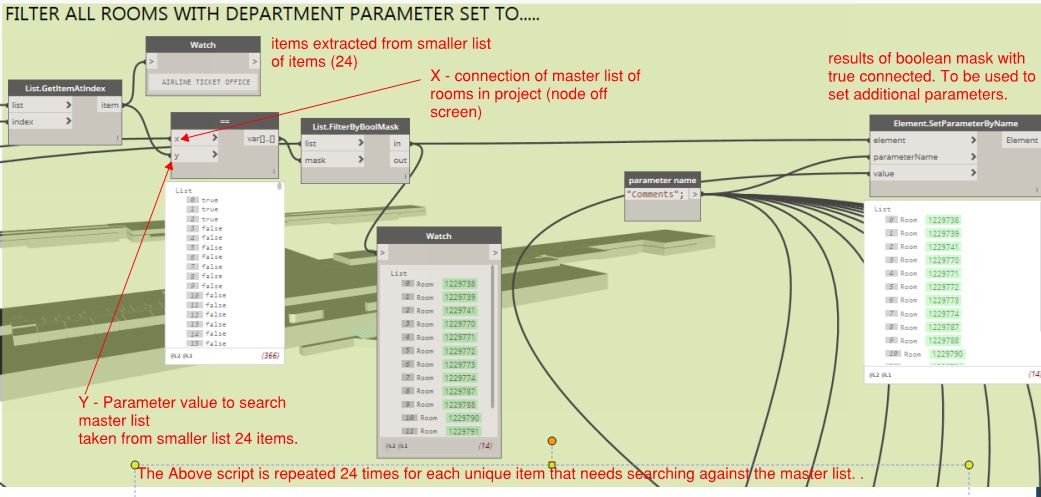
-The 24 unique values are then searched against the master list using boolean mask.
-I have repeated this process for the 24 unique items i need to search for.
.
DICTIONARIES: Dynamo 2.0 introduces the concept of separating the dictionary data type from the list data type. This change can pose some significant changes to how you create and work with data in your workflows. Prior to 2.0, dictionaries and lists were combined as a data type. In short, lists were actually dictionaries with integer keys.
-
What is a dictionary? A dictionary is a data type composed of a collection of key-value pairs where each key is unique in each collection. A dictionary has no order and basically you can “look things up” using a key instead of an index value like in a list. In Dynamo 2.0, keys can only be strings.
-
What is a list? A list is a data type composed of a collection of ordered values. In Dynamo, lists use integers as index values.
-
Why was this change made and why should I care? The separation of dictionaries from lists introduces dictionaries as a first-class citizen that you can use to quickly and easily store and lookup values without needing to remember an index value or maintain a strict list structure throughout your workflow. During user testing, we saw a significant reduction in graph size when dictionaries were utilized instead of several “GetItemAtIndex” nodes.
-
What are the changes?
-
Syntax changes have occurred that change how you will initialize and work with dictionaries and lists in code blocks.
- Dictionaries use the following syntax
{key:value}
- Lists use the following syntax
[value,value,value]
-
New nodes have been introduced to the library to help you create, modify, and query dictionaries.
- Lists created in 1.x code blocks will automatically migrated on load of the script to the new list syntax that uses square brackets instead of curly brackets { }
Be on the lookout for more documentation on dictionaries soon!
http://dynamobim.org/to-dynamo-2-0-and-beyond/
That was fast.
Thank you, I will take a look and provide more info if i need to.
Cheers,
If a Dictionary doesn’t work I believe I had a similar script I was writing recently with a similar issue, I fixed it with a single python node i wrote, if you share some more information as to what your exactly trying to put in and get out I may be able to tweak my node and share it with you.
Thank you although I’ve fallen at the first hurdle. I tried reinstalling version 2 but i keep have problems. My standard node library is missing. I will make a separate post for this issue so hopefully i can get 2.1 installed properly.
I have tried to use the dictionary nodes but could not get the results i wanted.
I have also tried the “string contains node”. It appears to be working but unfortunately I’m a little stuck now.
I have duplicated the master list of 366 items by 24 (which equals the amount of separate search items that i want to compare the master list to). By using the string contains node, each of the 24 lists containing 366 items is compared against the list containing 24 items in turn. This results in 24 lists of 366 items that correspond to the 24 separate searches by giving a true/false format. (Are you still with me?) I now need to somehow isolate the true items and obtain the parameters of the respective room and I’m not sure how to do this?
Make a copy of this script and simplify, get rid of all thats not the issue.
Clear your mind, take a walk, and come back to it if you have a new idea
Thanks for the advice.
The mass connectors you see was the first iteration where i copied the base script and changed the inputs for the strings i wanted.
I did take a walk  and when i came back i tried again using the nodes you see above to simplify.
and when i came back i tried again using the nodes you see above to simplify.
However the best i can do is the results you see in the string contains.
I’m going to shelf this for now and come back later.
Thanks.
This Dictionary mode of writing data… it’s like the node Springs.Dictionary used to do, or am i wrong?
I’m not using Dynamo 2.0 yet, and i would like to understand that. Can you explain the difference between the root Dictionary of DYnamo 2.0 and Springs.Dictionaries node?
Thank you!
I use the dictionaries just like you for now.
I’m on Dynamo1.3.2
I have a dictionary for Sheet Size, translating With and Height into A0, A1 and other sizes
I had read the article about dictionaries in 2.0 but have no experience with it.
Since the nodes from DynamoCanDo show the “auto” text for lacing, i knew he was on 2.0 or higher.
Below is an example with 66 Rooms in one list and 11 Departments in another.
Each of the Rooms already belongs to one of the 11 Departments.
The definition below assigns a common Comment to all Rooms in the same Department
group.dyn (15.4 KB) (ver 2)
group.rvt (1.3 MB)
Note: Attaching small files in the original post would help others understand your issue better.
Hi Vikram,
Thanks for your response. This is a clever approach and I appreciate it. Incredible!
Thank you.
Hello,
If I am not mistaken, you are trying to group rooms according to their department?
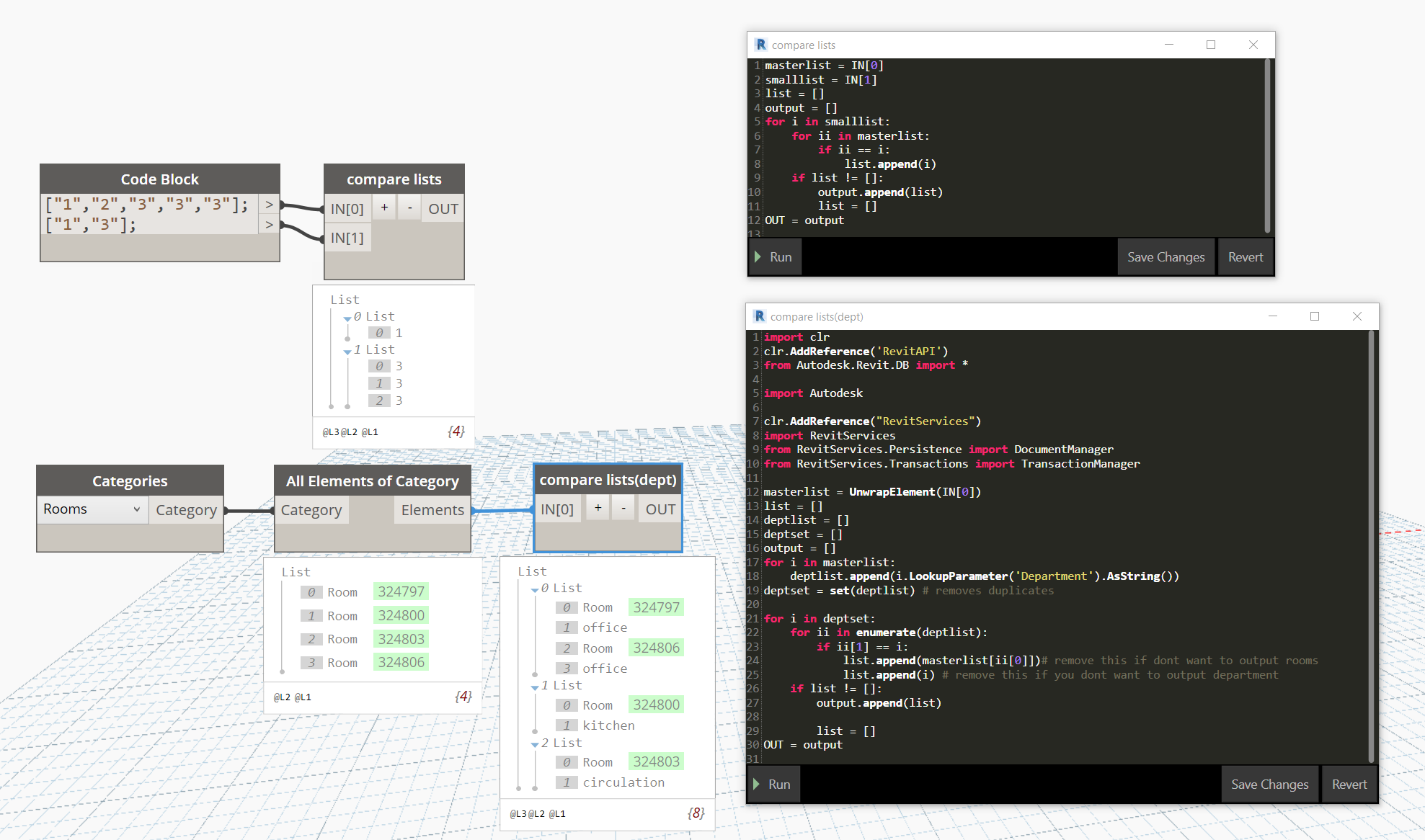
I made a couple of methods using python that would remove all of the bool mask filter clutter.
The first script is jsut a generic sorting tool you could use if you want to gather the departments seperately
masterlist = IN[0]
smalllist = IN[1]
list = []
output = []
for i in smalllist:
for ii in masterlist:
if ii == i:
list.append(i)
if list != []:
output.append(list)
list = []
OUT = output
Otherwise, I did my best to create something that would work for your purpose specifically, it might not be the most efficient but it is the only way I currently know as I am still new.
import clr
clr.AddReference('RevitAPI')
from Autodesk.Revit.DB import *
import Autodesk
clr.AddReference("RevitServices")
import RevitServices
from RevitServices.Persistence import DocumentManager
from RevitServices.Transactions import TransactionManager
masterlist = UnwrapElement(IN[0])
list = []
deptlist = []
deptset = []
output = []
for i in masterlist:
deptlist.append(i.LookupParameter('Department').AsString())
deptset = set(deptlist) # removes duplicates
for i in deptset:
for ii in enumerate(deptlist):
if ii[1] == i:
list.append(masterlist[ii[0]])# remove this if dont want to output rooms
list.append(i) # remove this if you dont want to output department
if list != []:
output.append(list)
list = []
OUT = output
I was not sure what exactly you want the output to be, but you could just remove one of the lines that add the element you do not need with the note.
Martin,
Thanks for your solution. I will try this out.
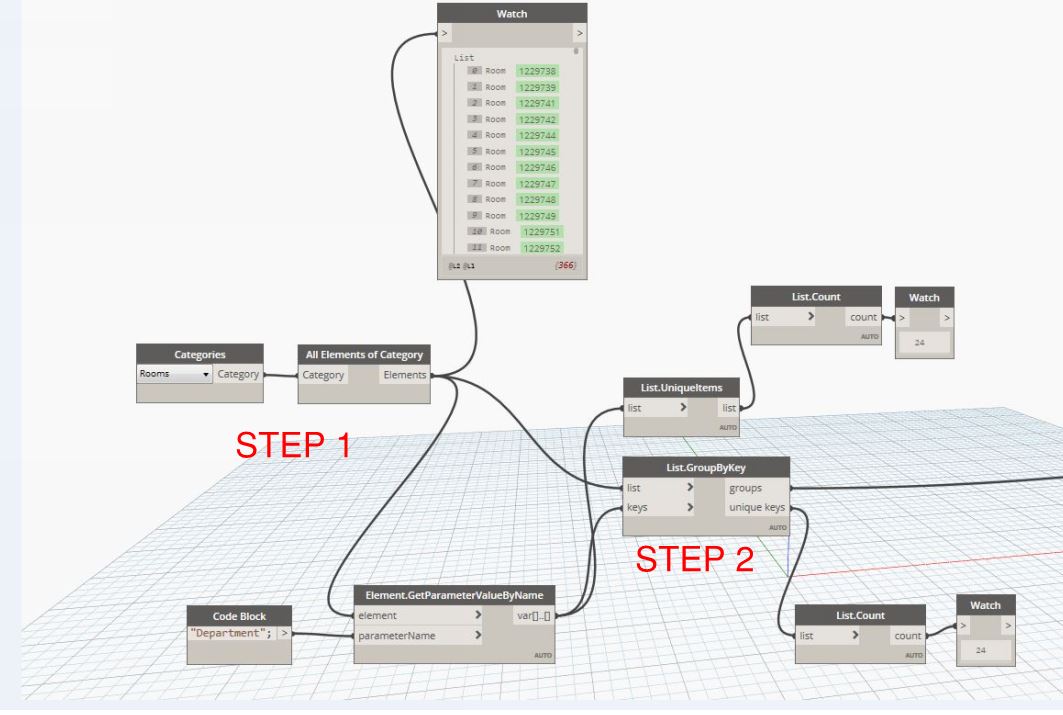
I thought I would share with you the current improved workflow all the same.
The task was to list the rooms in a project by the department name. Once the department name is obtained I then need to assign a loading function to this department list.
List All departments - List unique items - Assign loading function for each item.
Note - The loading functions can be simplified further and this would result in multiple departments having identical loading functions. However for this example we have used as many load functions as departments.
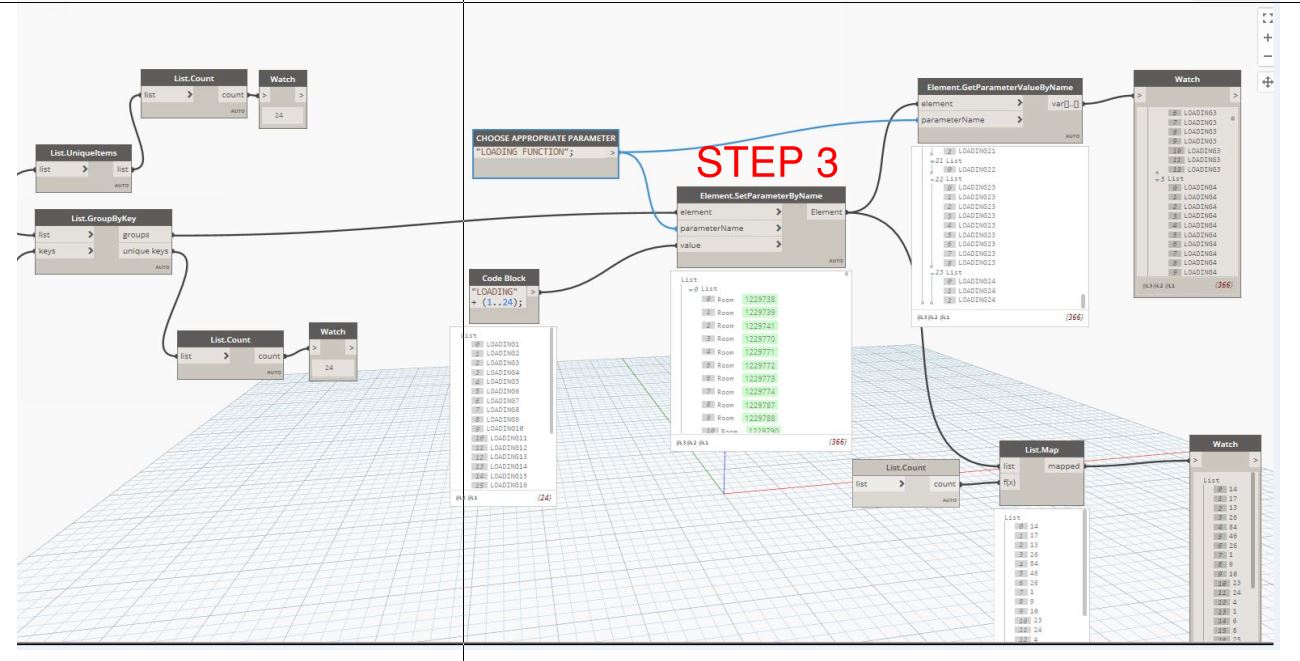
Step 1 - the rooms are listed by category and then by parameter value by name.
Step 2 - The list group key is used to group all items that share the same key.
Step 3- The groups are sent to the element set parameter by name. The appropriate parameter is entered and a list of value are entered that reflect the order of the original keys.
Note: step 3 code block generates a list and this could be replaced with an excel read in to create any parameter value required.
Thank you to Vikram for this. It was a great suggestion!
I see. The method I posted is similar to Vikram’s. It just uses one python node in lieu of group by key.
Does it matter what order the LOADING FUNCTION parameter is assigned to the rooms? As you can see, if you look at the room list, the sub-lists are ordered by the lowest numerical id value of all the rooms inside them. But if the order in which the sub-lists are labeled is arbitrary, then this method is perfectly fine. =)
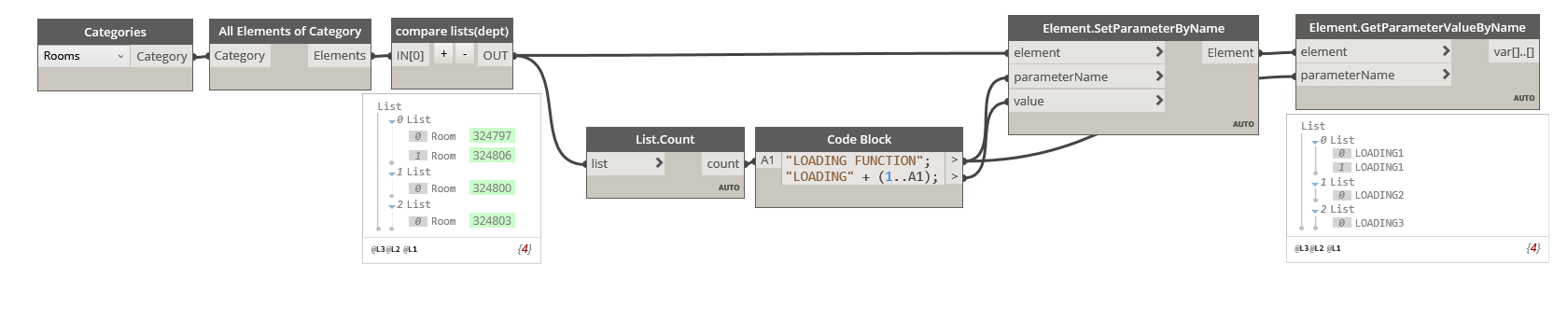
Here is a version of what you have but with the python node instead.
Another thing to note is that I used List.count instead of a magic number representing the amount of unique Departments. This is a good habit to have in case, for example, the number of Departments changes later on.
compare lists(dept):
import clr
clr.AddReference('RevitAPI')
from Autodesk.Revit.DB import *
import Autodesk
clr.AddReference("RevitServices")
import RevitServices
masterlist = UnwrapElement(IN[0])
list = []
deptlist = []
deptset = []
output = []
for i in masterlist:
deptlist.append(i.LookupParameter('Department').AsString())
deptset = set(deptlist) # removes duplicates
for i in deptset:
for ii in enumerate(deptlist):
if ii[1] == i:
list.append(masterlist[ii[0]])
if list != []:
output.append(list)
list = []
OUT = output
Hi there,
Thank you for this python solution. It will help simplify the script even further. It’s great to have an alternative and I can also use this as a template for similar tasks.
The order of the loading functions does not matter as the keys are derived from the first list of unique department values and these should maintain their relationship with the department names (if I’m understanding the list group by key node correctly.)
As for the count suggestion. Yes, this parametric approach is definitely more flexible than manually adjusting the list amount each time. I placed the count nodes for next time but for some reason did not use them for my example.
Thanks for your input. It’s been extremely valuable.