Trying to get my head round how Dynamo processes lists when you enter the custom node environment (one that I’m not too savvy in).
I’m making my own version of a Rhythm node for a script that’s using a version of the Rhythm package from before the node was added.
The code is working fine in the dynamo environment, but when I place it in a custom node environment it does something very strange to the list levels of the output and I cant seem to work out why?
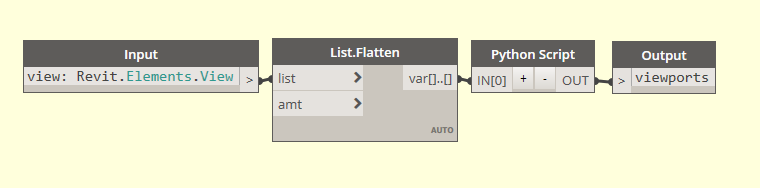
The Python script in the image below is the same code within the custom node called View.Viewport and is returning a nice list as expected with 2 levels. But with any input to the custom node I get the weird 4 level list you can see.
This is inside the node:
Finally this is the code:
import clr
clr.AddReference("RevitAPI")
import Autodesk
from Autodesk.Revit.DB import *
clr.AddReference("RevitServices")
import RevitServices
from RevitServices.Persistence import DocumentManager
doc = DocumentManager.Instance.CurrentDBDocument
def tolist(obj1):
if hasattr(obj1, "__iter__"): return obj1
else: return [obj1]
views = tolist(UnwrapElement(IN[0]))
viewports = FilteredElementCollector(doc).OfCategory(BuiltInCategory.OST_Viewports)
# ID of input views
view_IDs = [i.Id for i in views]
# filter all model viewports by input view ID
view_viewports = list(filter(lambda x: x.ViewId in view_IDs, viewports))
if len(view_viewports)<1:
OUT = "Views not on sheet"
else:
OUT = view_viewports
views = tolist(UnwrapElement(IN[0]))
viewports = FilteredElementCollector(doc).OfCategory(BuiltInCategory.OST_Viewports)
# ID of input views
view_IDs = [i.Id for i in views]
# filter all model viewports by input view ID
view_viewports = list(filter(lambda x: x.ViewId in view_IDs, viewports))
if len(view_viewports)<1:
OUT = "Views not on sheet"
else:
OUT = view_viewports
Any light shed on this one would be appreciated!
It can be a little confusing at first but the two work exactly the same but at different scales.
In the Dynamo workspace, all nodes have their own lacing and expected input structure (list vs item). Most nodes are smart enough to know when to iterate through different input structures based on lacing or list levels. When you convert a group of nodes to a custom node, the same logic applies. The thing to keep in mind here is that the custom node still has its own lacing and expected input structure at the graph level. The custom node will still attempt to iterate through different input structures that don’t match the way the node was written.
There are two ways to solve this:
-
When developing your custom node in the graph environment, write it specifically for the lowest combination of expected inputs. If one input requires a single item and the second input requires a single list, get your graph working with that structure first. When you convert to a custom node, the node will then expect those structures in the graph environment and work as expected. If you need to provide multiple inputs in your graph environment, then you can manipulate the lacing or list levels of the custom node to handle them. The same thing goes for python list structure. If you write your code when dealing with multiple testing inputs, then the custom node will expect that same structure and handle the inputs accordingly.
-
Along with option 1, or in place of it, you can objectively specify the input structure when defining the inputs of the custom node. This forces the node to use the specified structure when identifying inputs and should make the “auto iteration” of those inputs match your expectations.
For most of my custom nodes I use the input syntax as follows:
InputName: var[]..[]
This tells Dynamo to receive the input structure exactly as provided, and means you can use list levels as well if you want. I find any other syntax means dynamo makes assumptions about input structure and often gets it ‘wrong’ in a users view.
Edit: cheers for the fix @c.poupin
Hi Nick,
Thanks for the in-depth response here, it’s appreciated.
So I believe I did write my Python to handle any input structure as I have the function for catching if it is a list or an item.
Ultimately; if I’m understanding you correctly and I’ve written my code to handle either input type, the specified input structure of my node is what is forcing the node to handle a single view rather than process the whole list?
This is confirmed as the same code with @GavinNicholls 's suggestion for the VAR input outputs as I expected (thanks for that Gavin  ).
).
What I would like to understand is if it would be possible to define the input TYPE (so that people know only a view can be handled rather than var) but in a way that the input structure is retained i.e item/list.
Just to clarify one more time, your python code is not necessarily what I’m talking about in this case. Yes, you flatten everything and then pass it on to python which you’ve written to handle a list structure, which is good. That means that everything within the custom node will work, and in this case won’t throw any errors. But outside the custom node, in the graph environment, you could still specify list levels to control whether individual sublists are counted as unique inputs. That’s the behavior I’m talking about and how you can control the default or expected input structure.
However, it sounds like you have that working how you’d like. So for your second question, yes, you can specify the datatype for each input, but I believe you are limited. In fact I think you might be limited to global datatypes in this case, so you might not be able to specify Views or even Elements without moving to a ZeroTouch node. The notation is the same though. Just replace var with the datatype you want.